Sovereignty Series 11th Dec 2025Martin-Peter Lambert
Starting with the goal in mind, we must consider the framework for a sovereign digital Europe!
The Sovereignty Series (Bonus Chapter): The Verifiability Conundrum
We have built a framework for Europe’s digital sovereignty based on a powerful idea: mutual protection through verification. By embracing the Fallibility Principle—that no one is infallible—we have designed a system of Zero Trust Governance that protects the public from the abuse of power, and simultaneously protects those in power from false accusations, coercion, and risk. This is achieved by replacing trust with cryptographic proof in our digital sovereignty framework.
But this elegant solution creates a profound and complex challenge: the Verifiability Conundrum. A system that can verify everything can also see everything. How do we build a system that delivers radical accountability without becoming a tool of radical surveillance? How do we protect everyone, powerful and powerless alike, without making everyone transparent?
The Double-Edged Sword of Immutability
The core of our proposed system is an immutable, distributed ledger—a permanent, unchangeable record of official actions. This ledger framework allows the sovereign digital Europe initiative to protect a public official from false accusations; they can point to the ledger as a definitive, verifiable alibi. It is also the mechanism that convicts a corrupt official; the ledger provides an undeniable trail of their misconduct.
But this double-edged sword cuts both ways. If every official action is recorded, what about the actions of ordinary citizens? Does a request for a public service, a visit to a government website, or an application for a permit also become a permanent, immutable record? If so, we have not eliminated the potential for a surveillance state; we have perfected it. We have created a system that is technically incorruptible but potentially socially oppressive.
This is the heart of the conundrum. We need verifiability to protect against the fallibility of the powerful, but universal verifiability threatens the privacy and freedom of the powerless.
Resolving the Conundrum: Asymmetric Verifiability and Zero-Knowledge Proofs
The solution is not to abandon verifiability, but to apply it asymmetrically. We must build a system where the actions of the powerful are transparent, while the identities and data of the powerless are protected. This is not a contradiction; it is a design choice, enabled by modern cryptography.
Asymmetric Verifiability: We must distinguish between public acts and private lives within our sovereign digital Europe framework. The actions of an elected official or public servant, when performed in their official capacity, are public acts. They should be transparent and recorded on an immutable ledger for all to see. This is the price of power and the foundation of accountability. The actions of a private citizen, however, are private; they should not be recorded on a public ledger.
Zero-Knowledge Proofs (ZKPs): This is the cryptographic tool that makes Asymmetric Verifiability possible. As we discussed, ZKPs allow an individual to prove a fact is true without revealing the underlying data. A citizen can prove they are eligible for a government service (e.g., they are a resident, they are over 65, they meet an income requirement) without revealing their address, their exact age, or their salary. The government system can verify the eligibility without ever seeing or storing the personal data. The citizen’s interaction is verifiable, but their privacy is preserved within Europe’s digital sovereignty framework.
A System of Rights, Not a System of Surveillance
This model allows us to build a system that protects rights, not just data.
The Right to Accountability: The public has a right to a verifiable record of the actions of its servants. Asymmetric Verifiability delivers this within the sovereign digital Europe framework.
The Right to Privacy: Citizens have a right to interact with their government without having their lives turned into an open book. Zero-Knowledge Proofs deliver this.
This resolves the conundrum. We can have a system that is both radically transparent in its exercise of power and radically private in its treatment of citizens. The ledger records that a verified, eligible citizen received a service, but it does not record who that citizen was. The ledger records that a public official authorized a payment, and it records their name for all to see.
The New Social Contract
This is more than a technical architecture; it is a new social contract. It is a system that acknowledges the Fallibility Principle and designs for it. It protects leaders from the impossible burden of being perfect, and it protects the public from the inevitable consequences of that imperfection.
It is a system where a leader’s best defense is the truth, and where the public’s best defense is a system that makes that truth undeniable. It is a difficult, complex path, but it is the only one that leads to a framework for a sovereign digital Europe that is both secure and free.
The Wake – Up! It’s happening again – What to do when your CDN Fails
Surprise: The Day Cloudflare Stopped
It happened twice in two weeks. On December 5th and again in late November 2025, Mi Cloudflare — one of the world’s largest content delivery networks—experienced critical outages that briefly took portions of the internet offline. For millions of users, websites displayed error pages. For business owners, those minutes felt like hours. In situations like these, it’s crucial to know what to do when your CDN fails. For engineering teams, it sparked an urgent question: Are we really protected if our CDN is our only shield?
The answer is uncomfortable: most companies are not.
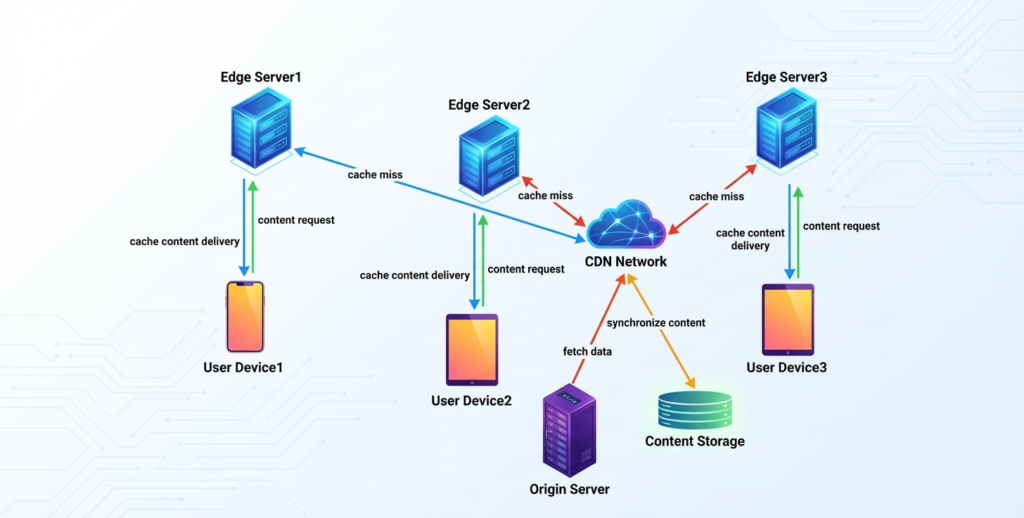
Figure 1: Traditional CDN architecture—single point of failure
If you operate a business whose entire web stack depends on a single CDN, this post is for you. We will walk through why single-CDN architectures are brittle at scale, and introduce two proven approaches to eliminate the risk: CDN bypass mechanisms and multi-CDN failover. By the end, you will understand how to design systems that keep serving your users even when a major vendor goes dark.
The Problem: Single Point of Failure at Global Scale
How a Single CDN Becomes Your Weakest Link
Most companies adopt a CDN for good reasons: faster content delivery, DDoS protection, global edge caching, and WAF (Web Application Firewall) services. The architecture looks simple and clean:
User → CDN → Origin Server
The CDN becomes the front door to everything. DNS resolves to the CDN’s IP addresses. The CDN caches static assets, forwards API traffic, and enforces security policies. The origin sits behind, protected from direct access.
This design works beautifully—until the CDN has a problem.
What Happened During the Outages
In both the November and December 2025 Cloudflare incidents, a configuration error or internal incident at Cloudflare’s control plane caused cascading failures across their global network. For affected customers, the symptoms were clear:
All traffic to Cloudflare-fronted services returned 5xx errors
DNS queries continued to resolve, but reached an unreachable service
Origin servers remained healthy and online, but were invisible to end users because all paths led through the CDN
Workarounds required manual intervention—logging into the CDN dashboard (if reachable), changing DNS, or calling support during an outage
The irony is sharp: the infrastructure designed to provide high availability became the source of unavailability.
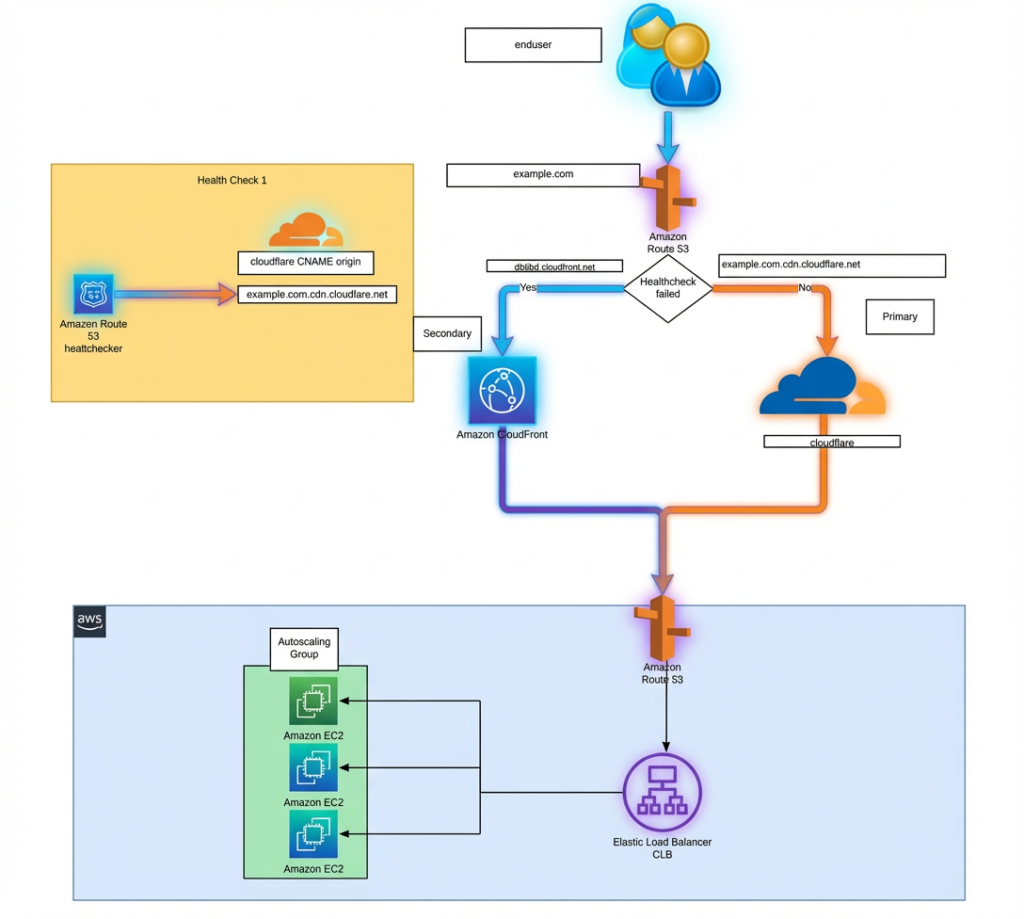
Figure 2: Multi-CDN failover strategy—removes single point of failure
The Business Impact
For a SaaS company with $100k monthly revenue, even 15 minutes of CDN-induced downtime can mean:
Potential SLA breaches and compensation obligations
Reputational damage in competitive markets
For fintech, healthcare, and e-commerce, the costs are exponentially higher. And yet, many teams assume “the CDN vendor will not fail” because they have redundancy internally.
They do. But you depend on them all the same.
Solution 1: CDN Bypass—The Emergency Exit
Why Bypass Matters
A CDN bypass is not about abandoning your primary CDN during normal operations. Instead, it is a controlled, secure pathway to your origin server that activates only when the CDN itself becomes the problem.
Think of it like a fire exit: you do not walk through it every day, but it saves lives when the main entrance is blocked.
How CDN Bypass Works
The architecture operates in layers:
Layer 1: Health Monitoring Continuous health checks on your primary CDN—latency, error rate, reachability, and geographic coverage. If thresholds are breached (e.g., 5% of regions report 5xx errors or p95 latency > 2 seconds), an alert is triggered and bypass logic is engaged.
Layer 2: Dual Routing You maintain two DNS records:
Primary: Points to your CDN (used under normal conditions)
Secondary / Bypass: Points to your origin or a hardened entry point (activated only on CDN failure)
Switching between them is automated—no manual DNS editing during an incident.
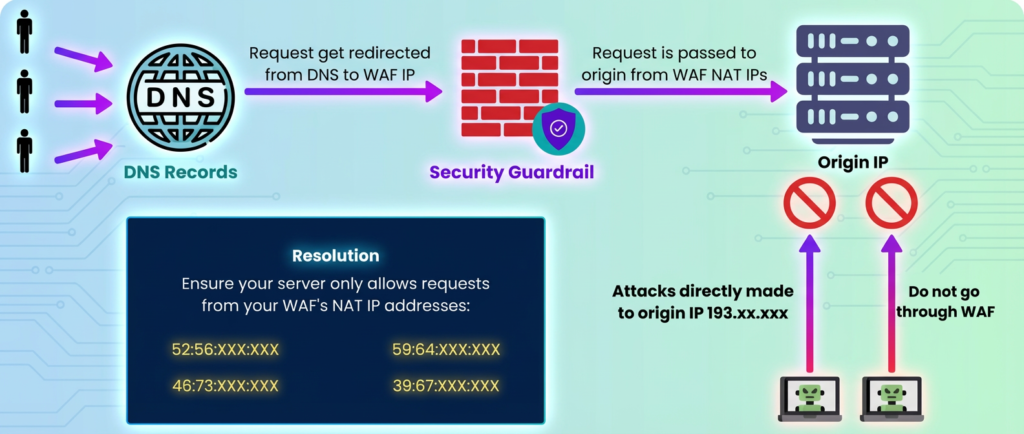
Layer 3: Origin Hardening Direct access to your origin is dangerous if uncontrolled. You must protect it with:
IP Allow-lists: Only accept requests from your bypass management service or approved monitoring endpoints
VPN / Private Connectivity: Route bypass traffic through a secure tunnel (e.g., AWS PrivateLink, Azure Private Link)
WAF and Rate Limiting: Apply the same security policies you had at the CDN to the direct path
Header Validation: Ensure only traffic from your bypass orchestration layer is accepted
Layer 4: Gradual Traffic Shift Once bypass is active, traffic does not all migrate at once. Instead:
Begin with 5-10% of traffic on the direct path
Monitor for errors and latency
Ramp up to 100% over 5-10 minutes
If issues arise, revert to CDN automatically
Figure 3: Origin server protection during bypass mode
The Bypass Playbook
A well-designed bypass system includes:
Automated Detection: Monitor CDN health continuously; do not wait for customer complaints
Runbook Automation: Execute failover logic without human intervention—speed is critical
Graceful Degradation: Bypass mode may not include all CDN features (like edge caching). Accept lower performance to avoid complete outage
Recovery and Rollback: Once the CDN recovers, automatically shift traffic back after a safety window
Incident Logging: Record what happened, when, and why for post-incident review
Who Should Use Bypass?
Bypass is ideal for:
E-commerce platforms, SaaS applications, and marketplaces where every minute of downtime is quantifiable revenue loss
Services with strict SLAs or compliance requirements (fintech, healthcare)
Teams with engineering capacity to operate a secondary resilience layer
Businesses that can tolerate reduced performance (no edge caching, longer latency) for short periods to stay online
It is not a replacement for a good CDN, but a safety net when your primary CDN fails.
Solution 2: Multi-CDN with Intelligent Failover
Moving Beyond Single-Vendor Lock-In
While CDN bypass solves the immediate problem, a more comprehensive approach is to distribute load across multiple CDN providers. This removes the single point of failure entirely and offers additional benefits: better performance, cost negotiation, and the ability to choose the best CDN for each use case.
Multi-CDN Architecture
In a multi-CDN setup, traffic is shared between two or more independent CDN providers:
Secondary CDN: Another global provider with complementary strengths — handles 30-40% of traffic
Routing Layer: DNS-based or HTTP-based intelligent routing that steers traffic based on real-time metrics
Figure 4: Network resilience with multi-CDN anomaly detection
How Intelligent Routing Works
Instead of static 50/50 load balancing, smart routing adjusts in real time:
Real-Time Metrics:
Latency: Route users to the CDN with lower p95 latency in their region
Error Rate: If one CDN returns 5xx errors >1%, shift traffic away automatically
Cache Hit Ratio: Some CDNs cache better for your content type; route accordingly
Regional Availability: If a CDN loses an entire region, route around it
Routing Methods:
DNS-Level (GeoDNS): Return different CDN A records based on user geography and health checks. Simplest but less granular
HTTP-Level (Application Layer): A small proxy or load balancer sits before both CDNs, making per-request decisions. More powerful but adds latency
Dedicated Multi-CDN Platforms: Third-party services (IO River, Cedexis, Intelligent CDN) manage routing and billing across multiple CDNs as a managed service
Practical Setup Example
DNS Query: cdn.example.com ↓ Resolver checks health of both CDNs ↓ CDN-A: Latency 50ms, Error Rate 0.1%, Status OK CDN-B: Latency 120ms, Error Rate 0.2%, Status OK ↓ Decision: Route to CDN-A ↓ User downloads content from CDN-A at 50ms
If CDN-A later spikes to 2% error rate:
Next query routes to CDN-B instead Existing connections may drain gracefully Traffic rebalances to healthy provider
Cache Warm-up and Cold Starts
One challenge with multi-CDN is that both CDNs must be warmed with your content. If you only route 30% of traffic to CDN-B, it will have more cache misses and higher latency to origin during the failover period.
Solutions:
Dual Caching: Proactively push your most critical assets to both CDNs daily
Warm Traffic: Send a small amount of traffic (10-20%) to the secondary CDN constantly to keep cache warm
Keep-Alive Connections: Maintain a baseline of requests to the secondary CDN even if not actively used
Unified Security and Configuration
For multi-CDN to work without surprising users, security policies must be consistent across both providers:
SSL/TLS Certificates: Same domain, same cert on both CDNs
WAF Rules: Mirror your DDoS and WAF policies between providers. A bypass to CDN-B should not have weaker protection
Cache Headers and Directives: Both CDNs should honor the same TTL and cache rules
Custom Headers and Transformations: If you inject headers or modify responses, do it consistently
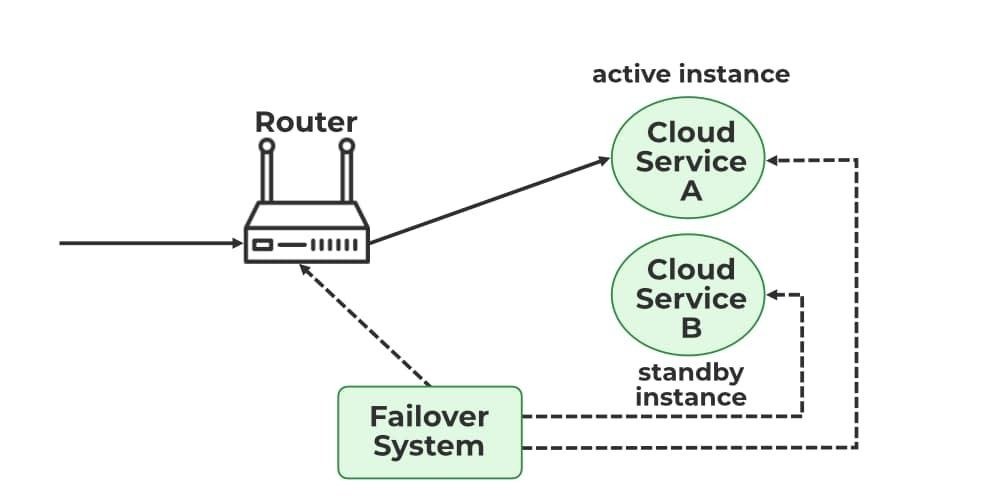
Figure 5: Failover system in cloud—automatic traffic rerouting
Who Should Use Multi-CDN?
Multi-CDN is ideal for:
Large enterprises serving global traffic where downtime has severe financial impact
Companies with high volumes that can negotiate favorable rates with multiple providers
Organizations that want to avoid vendor lock-in and maintain negotiating leverage
Businesses with diverse content types (streaming, APIs, static, dynamic) that benefit from specialized CDNs
Multi-CDN is more complex than single-CDN, but also more resilient and often cost-effective at scale.
Comparison: Single CDN, Bypass, and Multi-CDN
Aspect
Single CDN Only
CDN + Bypass
Multi-CDN
Availability During CDN Outage
High downtime risk
Critical paths online
Auto-rerouted
Setup Complexity
Low
Medium
High
Operational Overhead
Low
Medium
Medium-High
Cost
$$
$$$
$$$-$$$$
Performance (Normal State)
High
High
High (optimized)
Performance (Bypass/Failover)
N/A
Reduced (no edge cache)
Maintained
Security Consistency
Vendor-managed
Manual hardening needed
Must be unified
Time to Restore Service
Minutes to hours
Seconds (automatic)
Milliseconds (automatic)
Vendor Lock-In Risk
High
Medium
Low
Table 1: Table 1: Comparison of CDN resilience strategies
Designing for Your Organization
Assessment Questions
Before choosing bypass, multi-CDN, or both, ask yourself:
What is the cost of 1 hour of downtime? If it exceeds $10k, invest in resilience now.
Do we have geographic concentration risk? If most users are in one region where one CDN has weak coverage, diversify.
What is our incident response capability? Bypass requires automated systems; multi-CDN requires sophisticated routing. Do we have the team?
Is vendor lock-in a concern? If yes, multi-CDN reduces risk.
What is our compliance posture? Some industries require redundancy by regulation. Build it in from the start.
Phased Implementation Roadmap
Phase 1 (Weeks 1-4): Foundation
Audit current CDN configuration and dependencies
Identify critical user journeys (auth, checkout, APIs)
Design origin hardening and bypass playbooks
Set up continuous health monitoring
Phase 2 (Weeks 5-8): Bypass Ready
Implement health checks and alerting
Build DNS failover automation
Harden origin server access controls
Test bypass in staging; verify automatic recovery
Phase 3 (Weeks 9-12): Multi-CDN (Optional)
Onboard secondary CDN provider
Replicate security and cache configuration
Deploy intelligent routing layer
Gradual traffic shift and optimization
Each phase is low-risk if executed in staging first.
The Role of Managed Services
Building and operating these resilience layers yourself is possible but demanding. It requires:
Deep DNS and networking expertise
Continuous monitoring and alerting systems
Incident response runbooks and automation
Compliance and audit trails
24/7 on-call coverage for failover management
This is where specialized vendors and managed services add value. Services like Insight 42 help engineering teams:
Design resilient CDN architectures tailored to your traffic patterns and risk tolerance
Implement automated bypass and multi-CDN routing without reinventing the wheel
Operate these systems with 24/7 monitoring, alerting, and runbook execution
Optimize performance and cost by continuously tuning routing policies and cache behavior
Certify compliance and SLA adherence through detailed incident logging and remediation
A managed CDN resilience service typically pays for itself within one incident cycle by preventing revenue loss and reducing engineering overhead.
Next Steps: Start Your Assessment
The Cloudflare outages of November and December 2025 are not anomalies—they are signals that single-CDN dependency is a business risk, not a technical oversight.
You can take action today:
Run a scenario test: Imagine your primary CDN goes offline right now. Could your engineering team route traffic to an alternate path in under 5 minutes? If not, you have a gap.
Calculate your downtime cost: Quantify what one hour of unavailability means to your business in lost revenue, SLA penalties, and reputational damage.
Engage a resilience partner: Schedule a consultation to walk through bypass and multi-CDN options tailored to your infrastructure and risk profile.
We offer a free CDN Resilience Assessment where we review your current architecture, simulate a CDN failure, quantify business impact, and outline a concrete 12-week roadmap to eliminate single points of failure.
No vendor lock-in. No long contracts. Just pragmatic engineering that keeps your services online.
Azure Cloud Adoption Framework: A Structured Approach to Cloud Success
Azure CAF & Cloud Migration 27th Oct 2025Martin-Peter Lambert
Azure Cloud Adoption Framework: A Structured Approach to Cloud Success
The Microsoft Azure Cloud Adoption Framework (CAF) is a comprehensive methodology designed to guide organizations through their cloud adoption journey. It encompasses best practices, tools, and documentation to align business and technical strategies, ensuring seamless migration and innovation in the cloud. The framework is structured into eight interconnected phases: Strategy, Plan, Ready, Migrate, Innovate, Govern, Manage, and Secure. Each phase addresses specific aspects of cloud adoption, enabling organizations to achieve their desired business outcomes effectively.
The Strategy phase focuses on defining business justifications and expected outcomes for cloud adoption. In the Plan phase, actionable steps are aligned with business goals. The Ready phase ensures that the cloud environment is prepared for planned changes by setting up foundational infrastructure. The Migrate phase involves transferring workloads to Azure while modernizing them for optimal performance.
Innovation is at the heart of the Innovate phase, where organizations develop new cloud-native or hybrid solutions. The Govern phase establishes guardrails to manage risks and ensure compliance with organizational policies. The Manage phase focuses on operational excellence by maintaining cloud resources efficiently. Finally, the Secure phase emphasizes enhancing security measures to protect data and workloads over time.
This structured approach empowers organizations to navigate the complexities of cloud adoption while maximizing their Azure investments. The Azure CAF is suitable for businesses at any stage of their cloud journey, providing a robust roadmap for achieving scalability, efficiency, and innovation.
Below is a visual representation of the Azure Cloud Adoption Framework lifecycle:
The diagram illustrates the eight phases of the framework as a continuous cycle, emphasizing their interconnectivity and iterative nature. By following this proven methodology, organizations can confidently adopt Azure’s capabilities to drive business transformation.
What is Azure Cloud Adoption Framework (CAF):
The Azure Cloud Adoption Framework (CAF) is a comprehensive, industry-recognized methodology developed by Microsoft to streamline an organization’s journey to the cloud. It provides a structured approach, combining best practices, tools, and documentation to help organizations align their business and technical strategies while adopting Azure cloud services. The framework is designed to address every phase of the cloud adoption lifecycle, including strategy, planning, readiness, migration, innovation, governance, management, and security.
CAF enables businesses to define clear goals for cloud adoption, mitigate risks, optimize costs, and ensure compliance with organizational policies. By offering actionable guidance and templates such as governance benchmarks and architecture reviews, it simplifies the complexities of cloud adoption.
How Can Azure CAF Help Companies
Azure CAF provides several key benefits to organizations:
Business Alignment: It ensures that cloud adoption strategies are aligned with broader business objectives for long-term success.
Risk Mitigation: The framework includes tools and methodologies to identify and address potential risks during the migration process.
Cost Optimization: CAF offers insights into resource management and cost control to prevent overspending on cloud services.
Enhanced Governance: It establishes robust governance frameworks to maintain compliance and operational integrity.
Innovation Enablement: By leveraging cloud-native technologies, companies can innovate faster and modernize their IT infrastructure effectively.
How Insight 42 Can Help You Onboard to Azure CAF
At AMCA, we specialize in making your transition to Azure seamless by leveraging the Azure Cloud Adoption Framework. Here’s how we can assist:
Customized Strategy Development: We work with your team to define clear business goals and create a tailored cloud adoption strategy.
Comprehensive Planning: Our experts design detailed migration roadmaps while addressing compliance and security requirements.
End-to-End Support: From preparing your environment to migrating workloads and optimizing operations, we ensure a smooth transition.
Governance & Cost Management: We implement robust governance policies and provide cost optimization strategies for efficient resource utilization.
Continuous Monitoring & Innovation: Post-migration, AMCA offers ongoing support to manage workloads and foster innovation using Azure’s advanced capabilities.
With AMCA as your partner, you can confidently adopt Azure CAF while minimizing risks and maximizing returns on your cloud investment. Let us guide you through every step of your cloud journey.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.