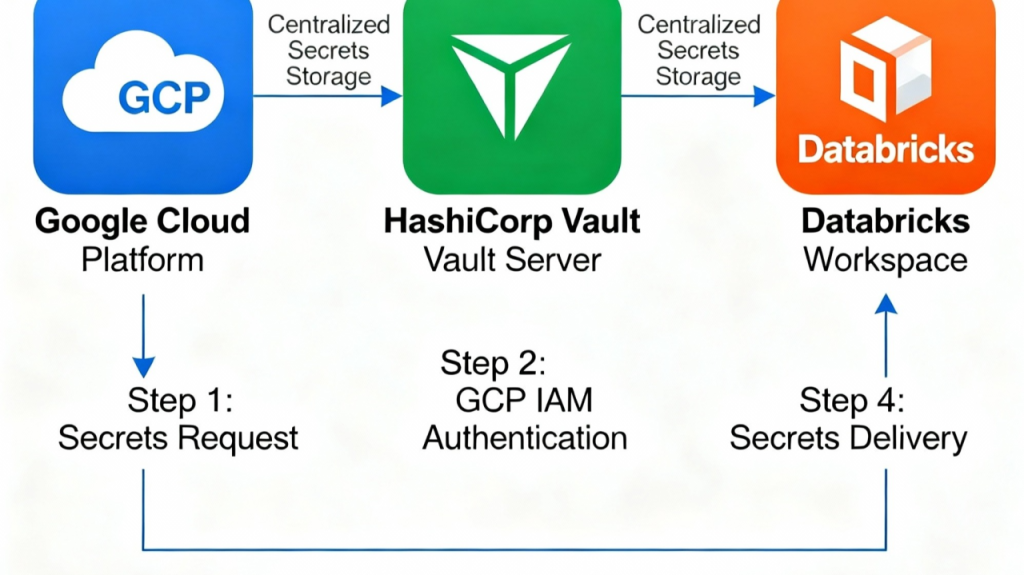
GCP DataBricks and Hashicorp Vault integration
Why Databricks on GCP Needs a Tool Like HashiCorp Vault
The modern data landscape presents complex security challenges that require sophisticated secrets management solutions. While Databricks on Google Cloud Platform offers powerful data processing capabilities, organizations face significant credential management hurdles that demand tools like HashiCorp Vault for comprehensive security.
The Credential Management Challenge
Databricks environments on GCP create a perfect storm for secrets management complexity. Organizations typically manage hundreds or thousands of sensitive credentials across multiple environments – development, staging, and production – each requiring access to various external services. This proliferation leads to secrets sprawl, where sensitive data becomes scattered across different platforms, making it difficult to track, secure, and manage effectively.
The collaborative nature of Databricks compounds these challenges. Data engineers, data scientists, and analysts frequently share notebooks and code, increasing the risk of inadvertent credential exposure. Without proper safeguards, sensitive information like API keys, database passwords, and service account tokens can easily leak through shared repositories or collaborative workspaces.
Security Vulnerabilities in Default Configurations
Recent security research has exposed critical vulnerabilities in Databricks platform configurations. Researchers discovered that low-privileged users could break cluster isolation and gain remote code execution on all clusters in a workspace. These attacks can lead to credential theft, including the ability to capture administrator API tokens and escalate privileges to workspace administrator levels.
The default Databricks File System (DBFS) configuration poses particular risks, as it’s accessible by every user in a workspace, making all stored files visible to anyone with access. This creates opportunities for malicious actors to modify cluster initialization scripts and establish persistent access to sensitive credentials.
Limitations of Native Databricks Secrets Management
While Databricks on Google Cloud offers Secret storage as Databricks Scoped Secrets or Databricks Secrets Backed by GCP secret manager/ Azure KeyVault as a native solution, it has significant limitations when integrated with complex Databricks workflows. GCP Secret Manager is tightly coupled to the GCP ecosystem, making it challenging to implement consistent secrets management across multi-cloud or hybrid environments. Organizations using Databricks often need to integrate with various external services, databases, and APIs that may not be Google Cloud native. It’s also reachable on a public network. Fine granular access is also a challenge .
And why would you like to even integrate Azure KeyVault with GCP Databricks if you are on GCP 😀.
HashiCorp Vault: The Strategic Solution
HashiCorp Vault addresses these challenges through several key capabilities that are particularly valuable for Databricks on GCP:
Dynamic Secrets Generation
Vault’s Google Cloud secrets engine generates temporary, short-lived GCP IAM credentials that automatically expire. This eliminates the security risks associated with long-lived static credentials, significantly reducing the window for potential credential misuse. For AI workloads on GCP, including those running on Databricks, this dynamic approach is crucial for maintaining security while enabling automated data processing.
Centralized Secrets Management
Vault provides a unified control plane for managing secrets across different environments and platforms. This centralization addresses the secrets sprawl problem by ensuring all sensitive data is stored in a single, secure location with comprehensive access controls. Development teams can retrieve secrets programmatically without hardcoding them into notebooks or configuration files.
Advanced Access Control and Auditing
Vault implements fine-grained access policies that can be customized based on roles, environments, and specific use cases. Every secret access is logged and auditable, providing the forensic trail necessary for compliance and security incident response. This is particularly important in Databricks environments where data governance and regulatory compliance are critical requirements.
Workload Identity Federation Support(Optional)
Vault now supports Workload Identity Federation (WIF) with Google Cloud, enabling secure authentication without requiring long-lived service account credentials. This integration minimizes credential sprawl and establishes a trust relationship between Vault and GCP services, reducing security concerns associated with manually created service accounts.
Implementation
Lets get to it , here I have provided configuration in Terraform and Bash cli, you can use any other method as well.
Note : Shared Databricks Clusters are not Supported, only dedicated clusters such as personal or job clusters.
Step 1: Configurations on GCP, Create an SA and grant project.viewer and serviceaccount.admin permissions
$ export GCP_PROJECT=<Your GCP project>
$ gcloud services enable --project "${GCP_PROJECT}" \
cloudresourcemanager.googleapis.com \
iam.googleapis.com
$ gcloud iam service-accounts create sa-vault \
--display-name "Vault Authenticator SA" \
--project "${GCP_PROJECT}"
$ gcloud projects add-iam-policy-binding \
"${GCP_PROJECT}" --member \
"serviceAccount:sa-vault@${GCP_PROJECT}.iam.gserviceaccount.com" \
--role "roles/viewer"
$ gcloud projects add-iam-policy-binding \
"${GCP_PROJECT}" --member \
"serviceAccount:sa-vault@${GCP_PROJECT}.iam.gserviceaccount.com" \
--role "roles/iam.serviceAccountKeyAdmin"
$ gcloud projects add-iam-policy-binding \
"${GCP_PROJECT}" --member \
"serviceAccount:sa-vault@${GCP_PROJECT}.iam.gserviceaccount.com" \
--role "roles/iam.serviceAccountTokenCreator"
$ gcloud iam service-accounts keys create sa-vault.json \
--iam-account "sa-vault@${GCP_PROJECT}.iam.gserviceaccount.com"Step 2: Configurations on Vault , I have used terrafrom , but you can use bash/cli as well.
terraform {
required_providers {
vault = {
source = "hashicorp/vault"
version = "~> 5.0.0"
}
}
}
provider "vault" {
address = "Your vault address"
# This is the configuration to run it locally with azuread auth - it will
# automatically login using a browser
# You can use some other auth method for vault as well
auth_login_oidc {
role = "azuread"
mount = "azuread"
}
}
variable "gcp_sa_admins" {
description = "List of GCP Sevice accounts for Vault admin role"
type = list(string)
default = [ "" ]
}
variable "gcp_sa_contributors" {
description = "List of GCP Sevice accounts for Vault contributor role"
type = list(string)
default = [ "" ]
}
variable "gcp_databricks_project" {
description = "List of GCP Sevice accounts for Vault contributor role"
type = list(string)
default = [ "" ]
}
resource "vault_gcp_auth_backend" "gcp" {
credentials = sa-vault.json
#Using all defaults, but you can customize
}
resource "vault_mount" "gcp" {
path = "gcp"
type = "kv"
options = { version = "2" }
}
resource "vault_kv_secret_backend_v2" "gcp" {
mount = vault_mount.gcp.path
max_versions = 0
delete_version_after = 0
cas_required = false
}
resource "vault_kv_secret_v2" "example_secret" {
mount = vault_mount.gcp.path
name = "common/example"
data_json = jsonencode({
"example_secret" = "some-value"
})
}
resource "vault_policy" "admin" {
name = "admin"
policy = <<-EOF
path "*" {
capabilities = ["create", "read", "update", "delete", "list", "sudo"]
}
EOF
}
resource "vault_gcp_auth_backend_role" "gce" {
role = "gcp-vault-admin"
type = "iam"
backend = vault_gcp_auth_backend.gcp.path
bound_service_accounts = var.gcp_sa_admins
token_policies = [vault_policy.admin.name]
max_jwt_exp = "30m"
}
resource "vault_policy" "vault_contributors" {
for_each = var.use_cases
name = "gcp/policies/gcp/databricks/contributors"
policy = <<EOF
path "gcp/data/databricks/*" {
capabilities = ["create", "read", "update", "delete", "list"]
}
path "gcp/metadata/databricks/*" {
capabilities = ["list"]
}
path "gcp/metadata/" {
capabilities = ["list"]
}
EOF
}
resource "vault_gcp_auth_backend_role" "gce" {
role = "vault-databrick-contributors"
type = "gce"
bound_projects = var.gcp_databricks_project
backend = vault_auth_backend.gcp.path
bound_service_accounts = var.gcp_sa_contributors
token_policies = [vault_policy.vault_contributors.name]
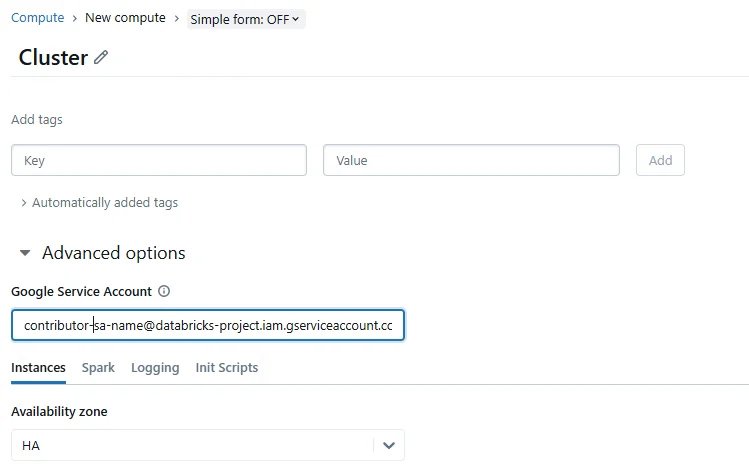
} Step 3: Configuration On Databricks Cluster , Set Google Service Account on the Databricks cluster
- Via UI : While creating cluster Navigate to Compute -> New compute –> Advanced Settings -> Google Service Account –> <Enter your GCP Service Account>
Via terraform
variable "gcp_sa_contributors" {
description = "List of GCP Sevice accounts for Vault contributor role"
type = list(string)
default = [ "" ]
}
data "databricks_node_type" "smallest" {
local_disk = true
}
data "databricks_spark_version" "latest_lts" {
long_term_support = true
}
resource "databricks_cluster" "shared_autoscaling" {
cluster_name = "Shared Autoscaling"
spark_version = data.databricks_spark_version.latest_lts.id
node_type_id = data.databricks_node_type.smallest.id
autotermination_minutes = 20
autoscale {
min_workers = 1
max_workers = 10
}
gcp_attributes {
google_service_account = var.gcp_sa_contributors
}
}Step 4: Accessing Secrets from Vault from databricks notebook or job connected to a dedicated cluster
Below is a sample python notebook code to access secrets, I recommend to write a python library to optimize the usage.
pip install hvac requests import requests
import hvac
def login_to_vault_with_gcp(role, vault_url):
# GCP metadata endpoint for the service account token
metadata_url = "http://metadata/computeMetadata/v1/instance/service-accounts/default/identity"
# Request the JWT token from the metadata server
headers = {"Metadata-Flavor": "Google"}
params = {"audience": f"http://vault/{role}", "format": "full"}
try:
jwt_token = requests.get(metadata_url, headers=headers, params=params).text
except requests.RequestException as e:
raise Exception(f"Failed to get JWT token: {e}")
# Log into Vault using the GCP method
client = hvac.Client(url=vault_url)
login_response = client.auth.gcp.login(role=role, jwt=jwt_token)
if 'auth' in login_response and 'client_token' in login_response['auth']:
print("Login successful")
client.token = login_response['auth']['client_token']
return client
else:
print("Login failed:", login_response)
return None
def list_secrets(client, path):
try:
list_response = client.secrets.kv.v2.list_secrets(mount_point=mount, path=path)
list_response = client.secrets.kv.v2.list_secrets(mount_point=mount, path=path)
print('The following paths and secrets are available under the path prefix: {keys}'.format(
keys=','.join(list_response['data']['keys']),
))
except hvac.exceptions.InvalidRequest as e:
print(f"Invalid request: {e}")
except hvac.exceptions.Forbidden as e:
print(f"Access denied: {e}")
except Exception as e:
print(f"An error occurred: {e}")
def create_secrets(client,mount, path,secretname):
try:
client.secrets.kv.v2.create_or_update_secret(mount_point=mount, path=path+"/"+secretname,secret=dict(mysecretkey='mysecretvalue'))
except hvac.exceptions.InvalidRequest as e:
print(f"Invalid request: {e}")
except hvac.exceptions.Forbidden as e:
print(f"Access denied: {e}")
except Exception as e:
print(f"An error occurred: {e}")
if __name__ == "__main__":
vault_url = "https://vault.com" # Replace with your vault hostname
role = "vault-databrick-contributors"
mount= "gcp" # Base path
path = "databricks" # Specify the path to list secrets
secretname = "test1"
# Log in to Vault and get the client
client = login_to_vault_with_gcp(role, vault_url)
print(client.token)
if client:
create_secrets(client,mount,path,secretname)
list_secrets(client, path)Conclusion: The Future of Secure Data Platforms
The integration of HashiCorp Vault with Databricks on GCP represents a critical evolution in data platform security. As organizations face increasingly sophisticated threats and stringent compliance requirements, traditional approaches to credential management are no longer sufficient.
HCP Vault Secrets and advanced features like Vault Radar are expanding security lifecycle management capabilities, enabling organizations to discover, remediate, and prevent unmanaged secrets across their entire IT estate. These tools help locate and secure credentials that developers often store insecurely in source code, configuration files, and collaboration platforms.
The architectural patterns demonstrated in this implementation provide a foundation for secure, scalable data operations that can grow with your organization’s needs. By adopting dynamic secrets, centralized management, and comprehensive auditing, teams can focus on deriving value from their data rather than managing security vulnerabilities.
The secure approach becomes the easy approach when organizations invest in proper tooling and architectural patterns. As cloud data platforms continue to evolve, the integration of enterprise-grade secrets management will become not just a best practice, but a fundamental requirement for any serious data operation.
Feel free to drop a message to myinfo@insight42.com if you have some questions or comments.