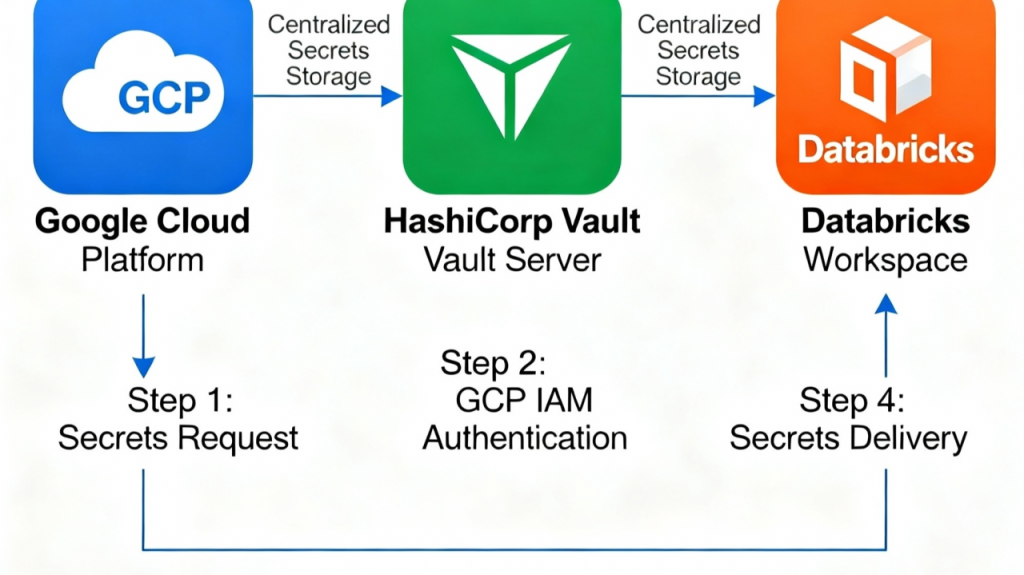
Warum Databricks auf GCP ein Tool wie HashiCorp Vault benötigt
Die moderne Datenlandschaft stellt komplexe Sicherheitsherausforderungen dar, die ausgefeilte Lösungen für das Geheimnismanagement erfordern. Während Databricks auf der Google Cloud Platform leistungsstarke Datenverarbeitungsfunktionen bietet, stehen Unternehmen vor erheblichen Hürden im Bereich des Anmeldeinformationsmanagements, die Tools wie HashiCorp Vault für umfassende Sicherheit erfordern.
Die Herausforderung des Anmeldeinformationsmanagements
Databricks-Umgebungen auf GCP schaffen einen perfekten Sturm für die Komplexität des Geheimnismanagements. Unternehmen verwalten typischerweise Hunderte oder Tausende sensibler Anmeldeinformationen in mehreren Umgebungen – Entwicklung, Staging und Produktion –, die jeweils Zugriff auf verschiedene externe Dienste benötigen. Diese Verbreitung führt zu einer Geheimnisverstreuung, bei der sensible Daten über verschiedene Plattformen verteilt werden, was es schwierig macht, sie zu verfolgen, zu sichern und effektiv zu verwalten.
Die kollaborative Natur von Databricks verschärft diese Herausforderungen. Dateningenieure, Datenwissenschaftler und Analysten teilen häufig Notebooks und Code, wodurch das Risiko einer unbeabsichtigten Offenlegung von Anmeldeinformationen steigt. Ohne angemessene Sicherheitsvorkehrungen können sensible Informationen wie API-Schlüssel, Datenbankpasswörter und Dienstkontotoken leicht über gemeinsam genutzte Repositories oder kollaborative Arbeitsbereiche durchsickern.
Sicherheitslücken in Standardkonfigurationen
Jüngste Sicherheitsforschung hat kritische Schwachstellen in den Konfigurationen der Databricks-Plattform aufgedeckt. Forscher entdeckten, dass Benutzer mit geringen Berechtigungen die Clusterisolation aufheben und Remote-Code auf allen Clustern in einem Workspace ausführen können. Diese Angriffe können zum Diebstahl von Anmeldeinformationen führen, einschließlich der Möglichkeit, Administrator-API-Token zu erfassen und Berechtigungen auf Workspace-Administratorebene zu eskalieren.
Die Standardkonfiguration des Databricks-Dateisystems (DBFS) birgt besondere Risiken, da sie für jeden Benutzer in einem Workspace zugänglich ist, wodurch alle gespeicherten Dateien für jeden mit Zugriff sichtbar sind. Dies schafft Möglichkeiten für böswillige Akteure, Cluster-Initialisierungsskripte zu ändern und dauerhaften Zugriff auf sensible Anmeldeinformationen zu erlangen.
Einschränkungen der nativen Databricks-Geheimnisverwaltung
Während Databricks auf Google Cloud die Speicherung von Geheimnissen als Databricks Scoped Secrets oder Databricks Secrets Backed by GCP Secret Manager/Azure Key Vault als native Lösung anbietet, weist es erhebliche Einschränkungen bei der Integration mit komplexen Databricks-Workflows auf. Der GCP Secret Manager ist eng mit dem GCP-Ökosystem verknüpft, was die Implementierung einer konsistenten Geheimnisverwaltung in Multi-Cloud- oder Hybridumgebungen erschwert. Organisationen, die Databricks verwenden, müssen häufig verschiedene externe Dienste, Datenbanken und APIs integrieren, die möglicherweise nicht Google Cloud-nativ sind. Es ist auch über ein öffentliches Netzwerk erreichbar. Feingranularer Zugriff ist ebenfalls eine Herausforderung.
Und warum sollten Sie Azure Key Vault überhaupt mit GCP Databricks integrieren wollen, wenn Sie GCP verwenden? 😀
HashiCorp Vault: Die strategische Lösung
HashiCorp Vault begegnet diesen Herausforderungen durch mehrere Schlüsselfunktionen, die besonders wertvoll für Databricks auf GCP sind:
Dynamische Geheimnisgenerierung
Die Google Cloud Secrets Engine von Vault generiert temporäre, kurzlebige GCP IAM-Anmeldeinformationen, die automatisch ablaufen. Dadurch werden die Sicherheitsrisiken im Zusammenhang mit langlebigen statischen Anmeldeinformationen beseitigt und das Zeitfenster für potenziellen Missbrauch von Anmeldeinformationen erheblich reduziert. Für KI-Workloads auf GCP, einschließlich solcher, die auf Databricks ausgeführt werden, ist dieser dynamische Ansatz entscheidend für die Aufrechterhaltung der Sicherheit bei gleichzeitiger Ermöglichung der automatisierten Datenverarbeitung.
Zentralisierte Geheimnisverwaltung
Vault bietet eine einheitliche Steuerungsebene für die Verwaltung von Geheimnissen in verschiedenen Umgebungen und Plattformen. Diese Zentralisierung behebt das Problem der unkontrollierten Verbreitung von Geheimnissen, indem sichergestellt wird, dass alle sensiblen Daten an einem einzigen, sicheren Ort mit umfassenden Zugriffskontrollen gespeichert werden. Entwicklungsteams können Geheimnisse programmatisch abrufen, ohne sie in Notebooks oder Konfigurationsdateien fest zu codieren.
Erweiterte Zugriffskontrolle und Überwachung
Vault implementiert fein abgestufte Zugriffsrichtlinien, die basierend auf Rollen, Umgebungen und spezifischen Anwendungsfällen angepasst werden können. Jeder Zugriff auf ein Geheimnis wird protokolliert und ist überprüfbar, wodurch die für die Einhaltung von Vorschriften und die Reaktion auf Sicherheitsvorfälle notwendige forensische Spur bereitgestellt wird. Dies ist besonders wichtig in Databricks-Umgebungen, in denen Daten-Governance und die Einhaltung gesetzlicher Bestimmungen kritische Anforderungen darstellen
Unterstützung für Workload Identity Federation (optional)
Vault unterstützt jetzt Workload Identity Federation (WIF) mit Google Cloud und ermöglicht so eine sichere Authentifizierung ohne die Notwendigkeit langlebiger Dienstkonto-Anmeldeinformationen. Diese Integration minimiert die Ausbreitung von Anmeldeinformationen und stellt eine Vertrauensbeziehung zwischen Vault und GCP-Diensten her, wodurch Sicherheitsbedenken im Zusammenhang mit manuell erstellten Dienstkonten reduziert werden.
Implementierung
Los geht’s! Hier habe ich die Konfiguration in Terraform und der Bash-CLI bereitgestellt. Sie können aber auch jede andere Methode verwenden.
Hinweis: Gemeinsam genutzte Databricks-Cluster werden nicht unterstützt, nur dedizierte Cluster wie z. B. persönliche Cluster oder Job-Cluster
Schritt 1: Konfigurationen auf GCP, Erstellen Sie eine SA und erteilen Sie project.viewer- und serviceaccount.admin-Berechtigungen.
$ export GCP_PROJECT=<Your GCP project>
$ gcloud services enable --project "${GCP_PROJECT}" \
cloudresourcemanager.googleapis.com \
iam.googleapis.com
$ gcloud iam service-accounts create sa-vault \
--display-name "Vault Authenticator SA" \
--project "${GCP_PROJECT}"
$ gcloud projects add-iam-policy-binding \
"${GCP_PROJECT}" --member \
"serviceAccount:sa-vault@${GCP_PROJECT}.iam.gserviceaccount.com" \
--role "roles/viewer"
$ gcloud projects add-iam-policy-binding \
"${GCP_PROJECT}" --member \
"serviceAccount:sa-vault@${GCP_PROJECT}.iam.gserviceaccount.com" \
--role "roles/iam.serviceAccountKeyAdmin"
$ gcloud projects add-iam-policy-binding \
"${GCP_PROJECT}" --member \
"serviceAccount:sa-vault@${GCP_PROJECT}.iam.gserviceaccount.com" \
--role "roles/iam.serviceAccountTokenCreator"
$ gcloud iam service-accounts keys create sa-vault.json \
--iam-account "sa-vault@${GCP_PROJECT}.iam.gserviceaccount.com"Schritt 2: Konfigurationen auf Vault, Ich habe Terraform verwendet, aber Sie können auch Bash/CLI verwenden.
terraform {
required_providers {
vault = {
source = "hashicorp/vault"
version = "~> 5.0.0"
}
}
}
provider "vault" {
address = "Your vault address"
# This is the configuration to run it locally with azuread auth - it will
# automatically login using a browser
# You can use some other auth method for vault as well
auth_login_oidc {
role = "azuread"
mount = "azuread"
}
}
variable "gcp_sa_admins" {
description = "List of GCP Sevice accounts for Vault admin role"
type = list(string)
default = [ "" ]
}
variable "gcp_sa_contributors" {
description = "List of GCP Sevice accounts for Vault contributor role"
type = list(string)
default = [ "" ]
}
variable "gcp_databricks_project" {
description = "List of GCP Sevice accounts for Vault contributor role"
type = list(string)
default = [ "" ]
}
resource "vault_gcp_auth_backend" "gcp" {
credentials = sa-vault.json
#Using all defaults, but you can customize
}
resource "vault_mount" "gcp" {
path = "gcp"
type = "kv"
options = { version = "2" }
}
resource "vault_kv_secret_backend_v2" "gcp" {
mount = vault_mount.gcp.path
max_versions = 0
delete_version_after = 0
cas_required = false
}
resource "vault_kv_secret_v2" "example_secret" {
mount = vault_mount.gcp.path
name = "common/example"
data_json = jsonencode({
"example_secret" = "some-value"
})
}
resource "vault_policy" "admin" {
name = "admin"
policy = <<-EOF
path "*" {
capabilities = ["create", "read", "update", "delete", "list", "sudo"]
}
EOF
}
resource "vault_gcp_auth_backend_role" "gce" {
role = "gcp-vault-admin"
type = "iam"
backend = vault_gcp_auth_backend.gcp.path
bound_service_accounts = var.gcp_sa_admins
token_policies = [vault_policy.admin.name]
max_jwt_exp = "30m"
}
resource "vault_policy" "vault_contributors" {
for_each = var.use_cases
name = "gcp/policies/gcp/databricks/contributors"
policy = <<EOF
path "gcp/data/databricks/*" {
capabilities = ["create", "read", "update", "delete", "list"]
}
path "gcp/metadata/databricks/*" {
capabilities = ["list"]
}
path "gcp/metadata/" {
capabilities = ["list"]
}
EOF
}
resource "vault_gcp_auth_backend_role" "gce" {
role = "vault-databrick-contributors"
type = "gce"
bound_projects = var.gcp_databricks_project
backend = vault_auth_backend.gcp.path
bound_service_accounts = var.gcp_sa_contributors
token_policies = [vault_policy.vault_contributors.name]
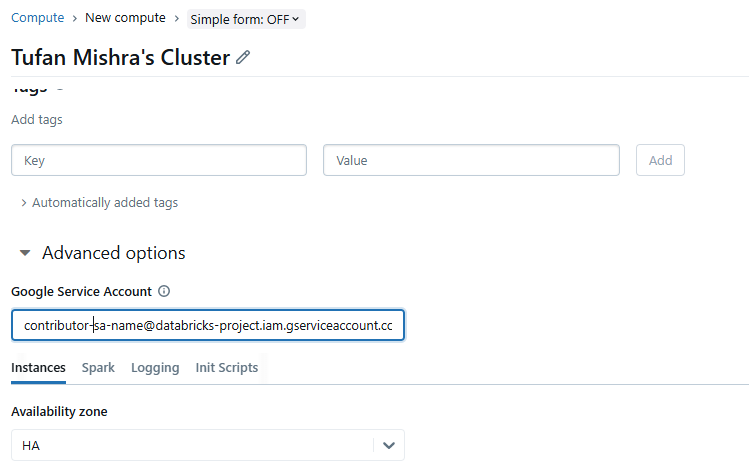
} Schritt 3: Konfiguration auf dem Databricks-Cluster, Richten Sie das Google-Dienstkonto auf dem Databricks-Cluster ein.
- Über die Benutzeroberfläche : Navigieren Sie beim Erstellen des Clusters zu Compute -> Neuer Compute -> Erweiterte Einstellungen -> Google-Dienstkonto -> <Geben Sie Ihr GCP-Dienstkonto ein>
Über Terraform
variable "gcp_sa_contributors" {
description = "List of GCP Sevice accounts for Vault contributor role"
type = list(string)
default = [ "" ]
}
data "databricks_node_type" "smallest" {
local_disk = true
}
data "databricks_spark_version" "latest_lts" {
long_term_support = true
}
resource "databricks_cluster" "shared_autoscaling" {
cluster_name = "Shared Autoscaling"
spark_version = data.databricks_spark_version.latest_lts.id
node_type_id = data.databricks_node_type.smallest.id
autotermination_minutes = 20
autoscale {
min_workers = 1
max_workers = 10
}
gcp_attributes {
google_service_account = var.gcp_sa_contributors
}
}Schritt 4: Zugriff auf Geheimnisse aus Vault von einem Databricks-Notebook oder -Job, der mit einem dedizierten Cluster verbunden ist
Unten finden Sie einen Beispielcode für ein Python-Notebook, um auf Geheimnisse zuzugreifen. Ich empfehle, eine Python-Bibliothek zu schreiben, um die Nutzung zu optimieren.
pip install hvac requests import requests
import hvac
def login_to_vault_with_gcp(role, vault_url):
# GCP metadata endpoint for the service account token
metadata_url = "http://metadata/computeMetadata/v1/instance/service-accounts/default/identity"
# Request the JWT token from the metadata server
headers = {"Metadata-Flavor": "Google"}
params = {"audience": f"http://vault/{role}", "format": "full"}
try:
jwt_token = requests.get(metadata_url, headers=headers, params=params).text
except requests.RequestException as e:
raise Exception(f"Failed to get JWT token: {e}")
# Log into Vault using the GCP method
client = hvac.Client(url=vault_url)
login_response = client.auth.gcp.login(role=role, jwt=jwt_token)
if 'auth' in login_response and 'client_token' in login_response['auth']:
print("Login successful")
client.token = login_response['auth']['client_token']
return client
else:
print("Login failed:", login_response)
return None
def list_secrets(client, path):
try:
list_response = client.secrets.kv.v2.list_secrets(mount_point=mount, path=path)
list_response = client.secrets.kv.v2.list_secrets(mount_point=mount, path=path)
print('The following paths and secrets are available under the path prefix: {keys}'.format(
keys=','.join(list_response['data']['keys']),
))
except hvac.exceptions.InvalidRequest as e:
print(f"Invalid request: {e}")
except hvac.exceptions.Forbidden as e:
print(f"Access denied: {e}")
except Exception as e:
print(f"An error occurred: {e}")
def create_secrets(client,mount, path,secretname):
try:
client.secrets.kv.v2.create_or_update_secret(mount_point=mount, path=path+"/"+secretname,secret=dict(mysecretkey='mysecretvalue'))
except hvac.exceptions.InvalidRequest as e:
print(f"Invalid request: {e}")
except hvac.exceptions.Forbidden as e:
print(f"Access denied: {e}")
except Exception as e:
print(f"An error occurred: {e}")
if __name__ == "__main__":
vault_url = "https://vault.com" # Replace with your vault hostname
role = "vault-databrick-contributors"
mount= "gcp" # Base path
path = "databricks" # Specify the path to list secrets
secretname = "test1"
# Log in to Vault and get the client
client = login_to_vault_with_gcp(role, vault_url)
print(client.token)
if client:
create_secrets(client,mount,path,secretname)
list_secrets(client, path)Fazit: Die Zukunft sicherer Datenplattformen
Die Integration von HashiCorp Vault mit Databricks auf GCP stellt eine entscheidende Weiterentwicklung der Datenplattformsicherheit dar. Da Unternehmen zunehmend komplexen Bedrohungen und strengen Compliance-Anforderungen gegenüberstehen, reichen traditionelle Ansätze für die Verwaltung von Anmeldeinformationen nicht mehr aus
HCP Vault Secrets und erweiterte Funktionen wie Vault Radar erweitern die Möglichkeiten des Sicherheitslebenszyklusmanagements und ermöglichen es Unternehmen, nicht verwaltete Geheimnisse in ihrer gesamten IT-Landschaft zu entdecken, zu beheben und zu verhindern. Diese Tools helfen dabei, Anmeldeinformationen zu finden und zu sichern, die Entwickler häufig unsicher in Quellcode, Konfigurationsdateien und Kollaborationsplattformen speichern.
Die in dieser Implementierung gezeigten Architekturmuster bilden die Grundlage für sichere, skalierbare Datenoperationen, die mit den Bedürfnissen Ihres Unternehmens wachsen können. Durch die Einführung dynamischer Geheimnisse, zentralisierter Verwaltung und umfassender Audits können sich Teams darauf konzentrieren, Wert aus ihren Daten zu schöpfen, anstatt Sicherheitslücken zu verwalten.
Der sichere Ansatz wird zum einfachen Ansatz , wenn Unternehmen in die richtigen Tools und Architekturmuster investieren. Da sich Cloud-Datenplattformen ständig weiterentwickeln, wird die Integration von Geheimnismanagement auf Unternehmensebene nicht nur zu einer Best Practice, sondern zu einer grundlegenden Voraussetzung für jede ernsthafte Datenoperation.
Senden Sie gerne eine Nachricht an myinfo@insight42.com, wenn Sie Fragen oder Anmerkungen haben.